무슨 일이 있었나
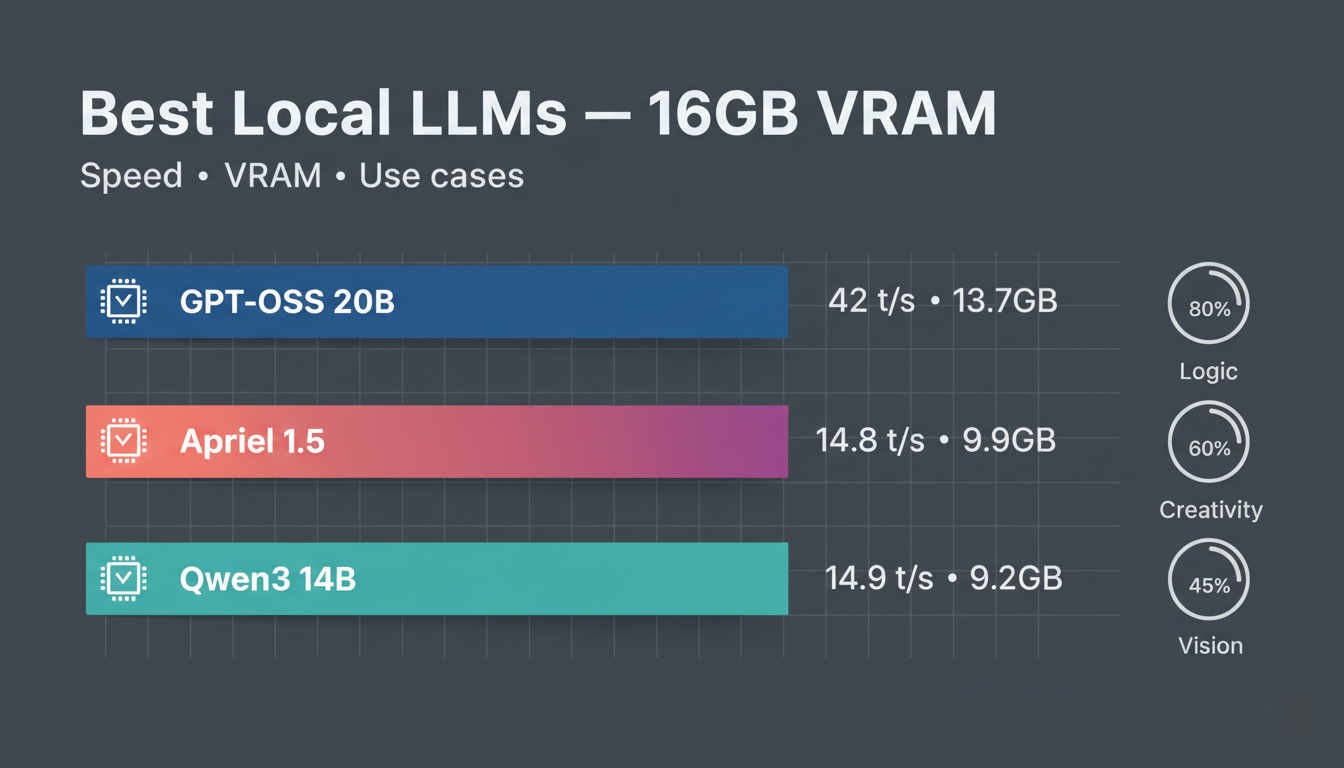
16GB VRAM으로 쓸 만한 로컬 LLM의 판도가 올해 확 바뀌었어. 2026년 벤치마크 기준으로 GPT-OSS 20B가 1위를 차지했는데, 42 tok/s로 경쟁 모델 대비 2.8배 빠르고 VRAM은 13.7GB밖에 안 쓰거든. 60K 컨텍스트에 논리 테스트 만점까지 찍었다.
왜 중요할까
그렇다고 GPT-OSS 20B만 답은 아니야. 지시 따르기(instruction-following)에선 Qwen3 14B가 속도와 능력의 균형이 제일 좋고, 코드 생성 전용으로는 Qwen 2.5 Coder 14B가 16GB VRAM 카테고리 최강이야. ollama pull qwen2.5-coder:14b로 바로 써볼 수 있다. 범용으로 쓰려면 Llama 3.3 8B, 처리량이 중요하면 Mistral Small 3 7B도 선택지에 들어가.
앞으로 볼 점
실전에서 중요한 건 이거야 — 20B 모델이 140 tok/s로 달리는 게 120B 모델을 양자화해서 12 tok/s로 돌리는 것보다 대부분의 실무에서 더 쓸 만해. RTX 4060 Ti 하나면 충분한 시대가 온 거야. 로컬 LLM을 처음 시도한다면 GPT-OSS 20B부터 깔아보고, 내 작업에 맞는지 테스트해보는 게 첫 번째 스텝이야.