무슨 일이 있었나
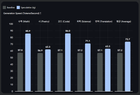
Gemma 4 31B에 작은 모델 하나 붙였을 뿐인데, 코드 생성이 50% 빨라졌어. r/LocalLLaMA에서 공유된 벤치마크를 보면, Gemma 4 E2B(4.65B)를 드래프트 모델로 쓰는 추론 가속 세팅에서 평균 29% 속도 향상이 나왔거든.
셋업은 RTX 5090(32GB VRAM), Windows 11, llama.cpp TurboQuant KV 캐시 포크 기반이야. 메인 모델은 Gemma 4 31B UD-Q4_K_XL(18.3GB), 드래프트 모델은 Gemma 4 E2B UD-Q4_K_XL(3.0GB)이고, 128K 컨텍스트로 돌렸어. 코드 생성 태스크에서 50%, 일반 텍스트에서도 20% 이상의 속도 개선이 나왔다고 해.
왜 중요할까
이게 주목받는 이유는 MoE 모델에서 추론 가속이 원래 까다롭기 때문이야. 드래프트 토큰 검증 시 활성화되는 전문가(expert)들의 합집합을 로드해야 해서 메모리 대역폭이 폭증하거든. 그런데 Gemma 4 31B는 Dense 모델이라 이 문제를 비껴가는 거야. 별도로 Thoughtworks가 만든 EAGLE3 드래프트 헤드는 1.72배 속도 향상을 달성했는데, 방식이 다르니 비교해볼 가치가 있어.
앞으로 볼 점
RTX 5090이 아닌 RTX 4070~4090급에서도 양자화 조합에 따라 비슷한 비율의 개선을 기대할 수 있다는 게 커뮤니티 반응이야. 로컬 LLM을 쓰고 있다면 드래프트 모델 세팅 한번 해볼 타이밍이야.