무슨 일이 있었나
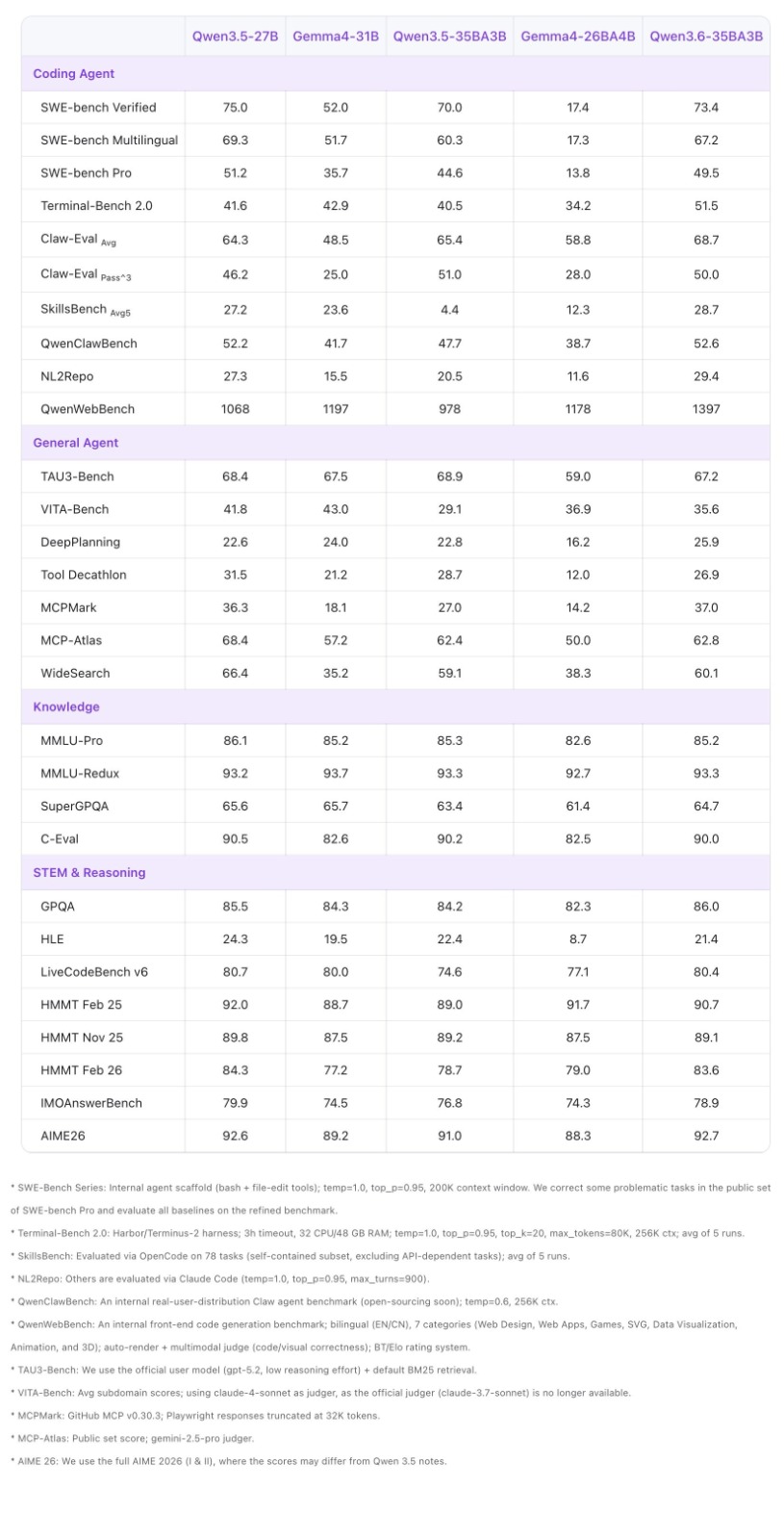
알리바바 Qwen 팀이 Qwen3.6-35B-A3B를 오픈 웨이트로 공개했다. 이름에 숫자가 두 개 붙는 게 포인트인데 — 35B가 전체 파라미터, 3B가 추론할 때 실제로 켜지는 파라미터거든. Sparse MoE(희소 혼합 전문가) 구조라서 35B짜리 모델을 3B 수준의 연산 비용으로 돌릴 수 있다는 얘기다.
성능 수치가 꽤 직관적으로 나왔어. 에이전트 코딩 벤치마크인 Terminal-Bench 2.0에서 51.5점, Google Gemma 4-31B의 42.9점보다 높다. SWE-bench Pro에서도 49.5 대 35.7이고. Simon Willison은 자기 블로그에 “Qwen3.6이 Claude Opus 4.7보다 펠리컨을 더 잘 그렸다”고 적었고, LocalLLaMA 커뮤니티에서도 빠르게 화제가 됐어.
왜 중요할까
컨텍스트 길이는 기본 262,144 토큰에 최대 100만 토큰까지 확장 가능하고, Apache 2.0 라이선스라 상업적으로도 자유롭게 쓸 수 있다. HuggingFace에 기본 버전과 FP8 퀀트 버전이 올라와 있고, Ollama에서도 ollama pull qwen3.6:35b-a3b로 바로 받을 수 있어.
앞으로 볼 점
로컬 코딩 에이전트를 세팅하려는 사람한테는 지금 시점에서 가장 현실적인 선택지 중 하나가 됐어. 3B 활성 파라미터면 RTX 3090 한 장으로도 돌릴 수 있고, 코딩 성능은 Gemma 4-31B를 넘는다는 게 포인트거든.