무슨 일이 일어났나
Artificial Analysis와 IBM이 기업 IT 운영용 에이전트 벤치마크 ITBench-AA를 공개했어. 첫 공개 범위는 SRE, 그러니까 Kubernetes 장애 대응 과제야. 2026년 5월 27일 발표됐고, UTC 기준 공개 시각을 KST로 보면 5월 28일 새벽에 잡히는 백필 기사야.
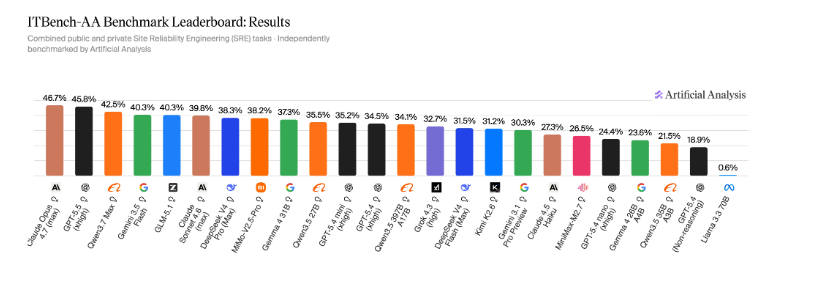
숫자로 보면
첫 SRE 세트는 59개 과제로 구성돼. 공개 과제 40개, 새로 만든 held-out, 그러니까 평가 때만 숨겨 두는 검증용 과제 19개야. Claude Opus 4.7이 47%, GPT-5.5가 46%, Qwen3.7 Max가 42%를 기록했고, 발표 글은 모든 frontier 모델이 50%를 넘지 못했다고 설명해.
평가 방식은
평가 방식도 꽤 빡빡해. 모델은 sandbox 안에서 다음 단서를 읽고 root-cause Kubernetes entity, 즉 장애를 일으킨 Kubernetes 대상을 제출해야 해.
- 로그: 장애가 언제 어떤 메시지로 드러났는지 보는 기록
- trace: 요청이 여러 구성요소를 지나간 경로
- metric: 지연, 오류율, 사용량처럼 숫자로 쌓이는 상태값
- topology: Deployment, Service, Pod 같은 구성요소의 연결 관계
100턴 제한 안에서 과제마다 3번 반복하고, 정답 root cause를 하나라도 놓치면 그 반복은 0점이야.
왜 중요할까
운영 장애 대응은 “대충 그럴듯한 설명”으로 끝나면 안 돼. 실제로 어떤 Deployment, Service, Pod, NetworkPolicy가 문제인지 좁혀야 하거든. ITBench-AA는 에이전트가 shell을 열고 자료를 뒤져서 원인을 찍는 구조라, 채팅 성능보다 운영 투입 리스크를 더 직접적으로 보여줘.
그리고 긴 추론이 항상 좋은 것도 아니었어. 발표 글은 Gemini 3.1 Pro Preview가 평균 83턴을 쓰고도 30%에 머문 반면, 더 짧은 trajectory, 즉 모델이 문제를 풀며 남긴 행동 경로가 더 나은 경우를 보여 줘. 많이 뒤진다고 정확히 좁히는 건 아니라는 뜻이야.
주의해서 볼 점
이건 “에이전트가 기업 IT를 못 한다”는 최종 판정이 아니야. SRE 첫 세트, 특정 harness, 그러니까 같은 조건으로 모델을 돌리는 평가 장치, 특정 채점식의 결과야. 그래도 운영팀 입장에서는 의미가 커. 모델 이름보다 아래 조건을 먼저 봐야 한다는 신호거든.